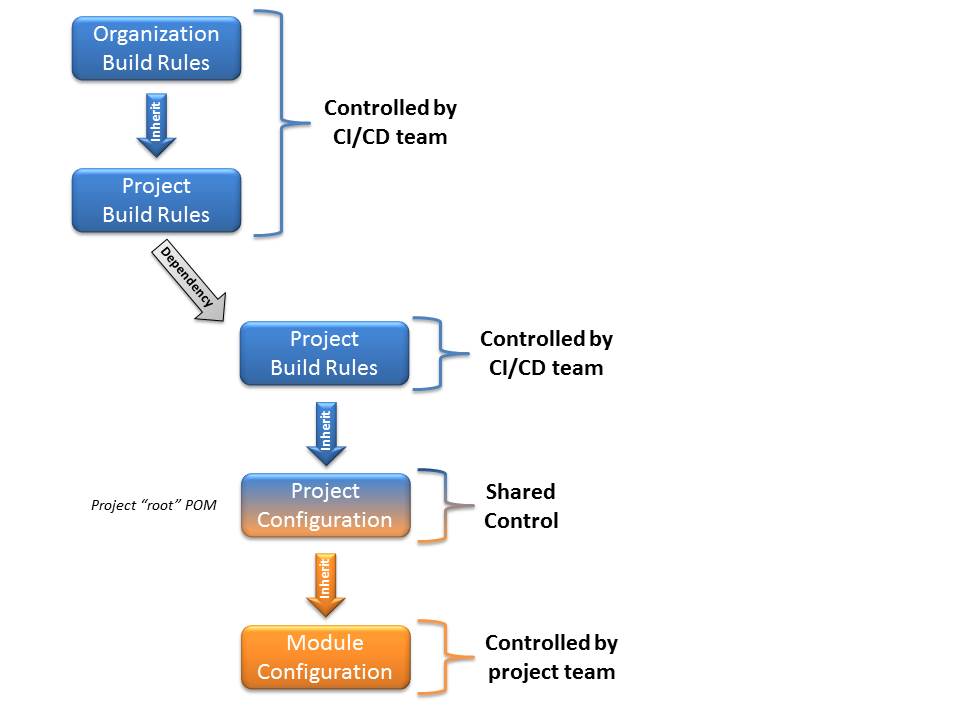
Creating secure binaries requires repeatable and reliable builds. Developers should have access to a set of approved tools, as well as a standardized configuration to run security and code quality checks in a consistent way.
Small projects commonly use an ad-hoc process to build software. However, when the teams get bigger, a more structured process proves beneficial. There are a variety of build tools available, some of them delivering a completely automated build, integration, and deployment value chain. Such CI/CD (Continuous Integration / Continuous Delivery [Deployment]) setups are increasingly popular in cloud deployments, where code changes are frequently promoted to production. In such setups, it is crucial to make the build/deploy process simple (“on the push of a button”), but also ensuring the quality of the produced artifacts.
Setting up such a CI/CD production chain is not a trivial task, and requires integration of automated processes, such as static code analysis, white box and black box testing, regression testing, and compliance testing just to name a few. Beyond tools used during the actual build, the CI/CD group is commonly also responsible for maintaining a stable development environment, starting from ensuring availability of dependencies used during the build over providing clean build machines up to maintaining the infrastructure used during any form of black box testing and even production.
Build management tools like Maven only cover a small aspect of the CI/CD deliverables. However, in combination with a source control server (like git), a repository server (like Nexus), and a CI system (like Jenkins) tools like Maven can deliver a surprisingly large set of functionality, and are often a good starting point for small to medium projects.
When creating a new Maven project, I generally recommend putting a few configuration constraints on the system to ensure a minimum amount of build reliability and repeatability. Some of these constraints are more relevant when building commercial products, while others are also helpful for non-commercial builds.
A key constraint is dependency management and dependency retention. It should always be guaranteed that a build can be re-executed at any point from a specific state (e.g. a “tag”) in the source control system. This is not a trivial requirement, as Maven, for example, offers “SNAPSHOT” dependencies that can change frequently. When such a SNAPSHOT dependency is referenced in a Maven project POM file, it is practically impossible to recreate a specific build due to the dynamic nature of these dependencies. These potential inconsistencies are one of the reasons why SNAPSHOTS are disappearing from public repositories such as Maven Central.
It is important to notice though that SNAPSHOTS are not a bad thing per se. They are a very valuable tool during development, as they allow frequent builds (and releases) without cluttering repository servers. Sometimes, an important feature in a library is only available as a SNAPSHOT. This happens frequently in smaller projects that do not release very often.
If a required dependency is only available as a SNAPSHOT, it should still not be used in a production build. Instead, it is better to deploy it in a custom repository server (such as a local Nexus server) as a RELEASE dependency, using e.g. a version number and a timestamp to identify the SNAPSHOT it has been created from.
A local Nexus server not only helps with SNAPSHOT dependency management, but is also a powerful tool to control the upstream dependencies in a project and ensure that these dependencies stay available. As an example, if a project depends on an obscure third party repository that could go away any moment because the third party developers chose a poor hosting setup (temporary unavailability) or lose interest in the project (permanent unavailability), the project is always in jeopardy of temporarily failing builds or, in the worst case, becoming unbuildable. Repository servers like Nexus can be configured as a proxy that sits between the local project and all upstream repositories. Instead of configuring the upstream repositories in the POM, overwrite the remote repository with the id “central” with the proxy server. From this point on, all dependencies will be loaded through the proxy and be permanently cached:
<repositories>
<repository>
<id>central</id>
<name>Your proxy server</name>
<url>http://your.proxy.server/url</url>
<layout>default</layout>
<snapshots>
<!-- Set this to false if you do not want to allow SNAPSHOTS at all -->
<enabled>true</enabled>
</snapshots>
<releases>
<updatePolicy>never</updatePolicy>
</releases>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>central</id>
<name>Your proxy server</name>
<url>http://your.proxy.server/url</url>
<layout>default</layout>
<snapshots>
<!-- Set this to false if you do not want to allow SNAPSHOTS at all -->
<enabled>true</enabled>
</snapshots>
<releases>
<updatePolicy>never</updatePolicy>
</releases>
</pluginRepository>
</pluginRepositories>