
As discussed earlier [1, 2], the Secure Software Development Lifecycle (SSDLC) process that I commonly use has an inner core that is built around policies, standards, and best practices, and an outer shell of ongoing activities around security training and education.
The middle circle groups the activities that need to be performed for every release of the product. It does not matter whether the product team is using, for instance, a waterfall model or an agile model; the basic activities are always the same. It is obvious though that in an agile model, where the release cycles are much shorter, some of the activities take considerably less time. This allows the agile team to keep their short release cycle, and the respective SSDLC activities to benefit from early “customer” feedback, which is an integral part of the agile philosophy. Depending on the project, the “customer” can vary, sometimes even between cycles: this role can be filled by company internal customers, operations teams, integration teams, external customers, and many more.
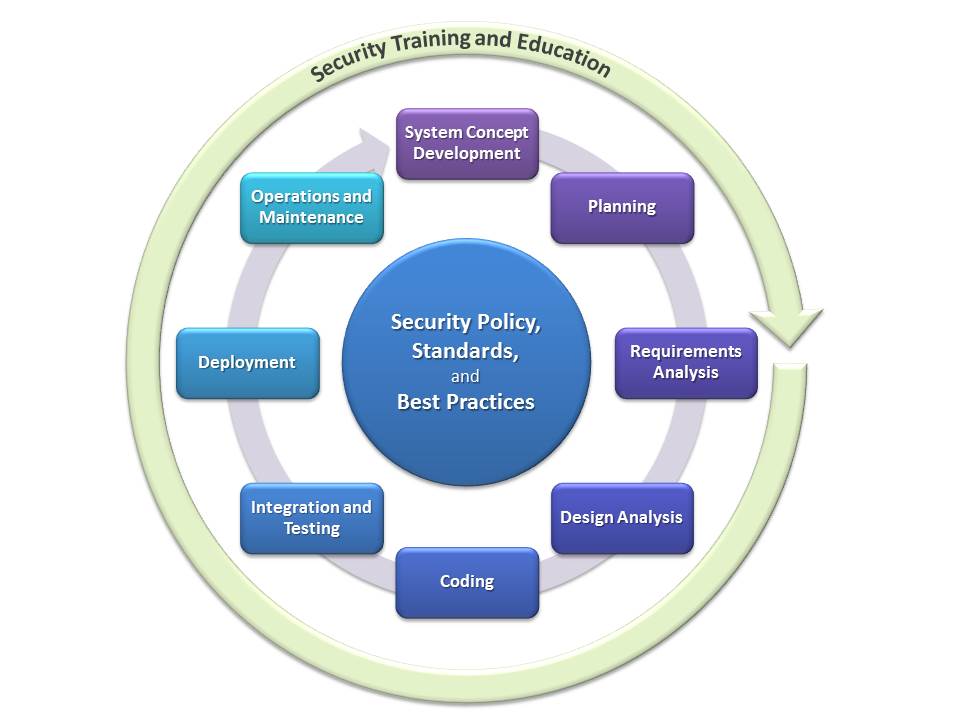 There are eight activities in the SSDLC, and each of the activities can be its own more or less complex process. The content of the “activity boxes” generally depends on the development model and the type of project, but I found the following definitions to be pretty universal and a good starting point:
There are eight activities in the SSDLC, and each of the activities can be its own more or less complex process. The content of the “activity boxes” generally depends on the development model and the type of project, but I found the following definitions to be pretty universal and a good starting point:
1. System Concept Development
This activity answers important questions on a comparatively high level for executives, but it is also a good elevator pitch. Questions that need to be answered here are things like: What should the system do? Does it integrate with existing solutions? What is the value add (both intrinsic and extrinsic)? Did anyone else already build this? Why should we build this? Is the solution worth funding? In particular the last question is very interesting for everyone involved. If there are specific security implications (e.g. from a system managing PII), this should have already come up in the discussion by this point.
2. Planning
This is basic project management 101. At this time, a core team has usually been appointed for the project, and roles have been assigned within the core team (remember, this holds both for waterfall and agile models, where roles may change once a Potentially Shippable Increment [PSI] has been completed). Questions answered at this stage include things like: What needs to be built? Do we have all the resources we need to complete this iteration? What are the timeframes? Are there dependencies on other groups, or are other groups depending on this project release? Toward the end of this stage, the epics implemented in this phase will be known with high certainty, which allows the security architect to start thinking about their security implications.
3. Requirements Analysis
The requirements analysis is somewhat intertwined with the planning activities. In particular in agile development models, it is not uncommon that teams jump back and forth between planning and requirements analysis, although this happens less frequently the further the agile project progresses. A specific part of the requirements analysis is the security requirements analysis. As in a regular requirements analysis, a lot of the work is driven by the product vision and system concept, as well as the relevant standards, policies, and industry best practices. Based on a security and privacy risk assessment, the team should establish a solid set of security and privacy requirements, as well as quality requirements that will later on help establish acceptance criteria for implemented features.
4. Design Analysis
Once the requirements analysis is complete, the team should have a pretty solid understanding of the “what” they want to build. The design analysis answers the questions around “how” things should be built. The first step in the design analysis requires the architects to create design specifications that include major system components, with information about the type of data these components are processing, the users that are accessing them, and the trust zones in which they are operated. Part of the general design analysis is the threat analysis, which will produce a set of design requirements based on an attack surface analysis. The threat modelling process is probably the most complex part in a Secure Software Development Lifecycle process, and while there are tools and methodologies available that help structuring this process and make it repeatable, it usually requires a skilled security architect.